

开源的交互式视频/图像标注工具
源代码
https://www.gitpp.com/japxin/project0808cvat
专为计算机视觉任务设计,支持目标检测、图像分割、姿态估计等任务
MIT协议,可以自有使用,商业化和二开
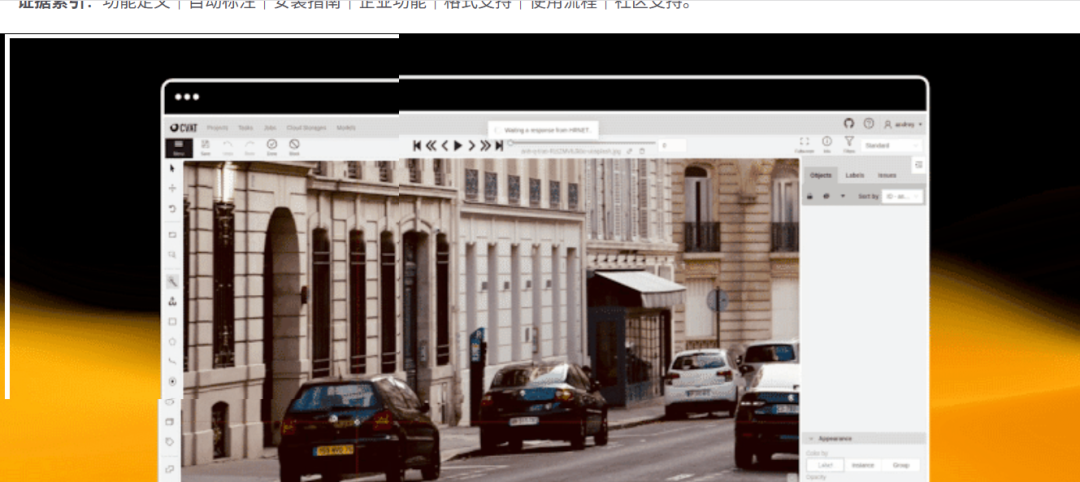
已被全球数以万计的用户和公司所使用。 使命是帮助世界各地的开发者、公司和组织使用以数据为中心的 AI 方法解决实际问题。
支持多种注释格式。点击“上传注释”和“转储注释”按钮 后,即可选择格式。Datumaro数据集框架允许使用其命令行工具和 Python 库进行额外的数据集转换
核心特性:
- 多任务支持
: -
目标检测(矩形框、多边形、关键点) -
图像分割(语义分割、实例分割) -
姿态估计(骨架标注) -
视频跟踪(插值标注、自动跟踪) - 高效协作
: -
基于Web的界面,支持多用户实时协作标注 -
任务分配与权限管理(管理员、标注员、质检员) -
标注进度跟踪与质量检查 - 格式兼容性
: - 导入/导出
:CVAT XML、PASCAL VOC、YOLO、COCO、TFRecord、MOT等 - 集成Datumaro
:通过命令行工具或Python库实现数据集转换、合并、过滤(如COCO→YOLO格式转换) - 自动化与扩展性
: -
支持TensorFlow OD API预标注,减少手动操作 -
提供API和Python SDK,可集成到现有工作流 -
Docker容器化部署,支持私有化安装与企业级服务(SSO、LDAP集成) - 社区与生态
: -
GitHub Stars超30k,被Intel等企业用于标注百万级数据 -
与Roboflow、HuggingFace等平台集成,支持模型推理结果可视化
适用场景:
-
自动驾驶(3D点云标注、多传感器融合) -
医疗影像分析(器官分割、病灶标注) -
安防监控(行为识别、目标跟踪) -
零售(商品检测、货架分析)
在机器视觉开发中,数据标注是将原始数据(如图像、视频、点云)转化为机器可理解格式的关键过程,其核心目标是为模型提供带有标签的监督信号,使其能够学习到数据中的模式与特征。以下是数据标注的详细流程、关键环节及技术要点:
一、数据标注的核心流程
- 需求分析与任务定义
- 示例
:COCO数据集规定“人”的标签为 person,且遮挡超过50%的目标可不标注。 - 示例
:自动驾驶中的车道线检测需标注多边形;人脸识别需标注关键点(眼睛、鼻子等)。 - 明确任务类型
:根据机器视觉任务(如目标检测、语义分割、姿态估计)确定标注类型。 - 定义标注规范
:制定统一的标注标准(如标签命名、颜色编码、最小标注尺寸),确保数据一致性。 - 数据采集与预处理
- 数据来源
:通过摄像头、传感器、公开数据集或合成数据(如GAN生成)获取原始数据。 - 数据清洗
:剔除低质量数据(如模糊、遮挡严重、重复样本),平衡类别分布(避免数据偏差)。 - 预处理
:调整分辨率、归一化像素值、裁剪ROI(感兴趣区域)以减少标注工作量。 - 标注工具选择与配置
-
设置快捷键(如快捷键切换标签类别)提升效率。 -
集成预标注模型(如YOLOv8初始化检测框)减少手动操作。 -
配置协作功能(如任务分配、权限管理)支持多人标注。 - 工具选型
:根据任务复杂度选择工具(如CVAT适合企业级标注,LabelImg适合轻量级检测任务)。 - 工具配置
: - 标注执行与质量控制
- 交叉验证
:多人标注同一数据,计算IoU(交并比)或Dice系数评估一致性。 - 抽样检查
:随机抽查标注结果,确保符合规范(如边界框紧贴目标边缘)。 - 迭代修正
:根据模型训练反馈(如低置信度预测)回溯修正标注错误。 - 手动标注
:人工绘制边界框、多边形或关键点。 - 半自动标注
:利用模型预测结果(如Mask R-CNN生成分割掩码)人工修正。 - 自动标注
:通过规则引擎(如颜色阈值分割)或传统算法(如霍夫变换检测直线)生成初始标注。 - 标注方法
: - 质量控制
: - 标注结果导出与格式转换
- 导出格式
:根据训练框架选择格式(如YOLO的 .txt、COCO的.json、PASCAL VOC的.xml)。 - 格式转换
:使用Datumaro、COCO API等工具转换格式(如将CVAT标注转为YOLO格式)。 - 数据增强
:在标注后应用旋转、翻转、裁剪等操作扩充数据集,提升模型泛化能力。 - 数据集版本管理与迭代
- 版本控制
:使用DVC(Data Version Control)或Git LFS管理标注数据,记录变更历史。 - 持续更新
:根据模型性能(如漏检、误检)补充难样本或调整标注策略(如细化类别标签)。
二、关键技术挑战与解决方案
- 标注效率与成本的平衡
-
使用弱监督学习(如图像级标签替代像素级标注)减少标注量。 -
开发交互式标注工具(如点击目标中心自动生成边界框)。 -
众包标注(如Amazon Mechanical Turk)结合人工审核降低成本。 - 挑战
:手动标注耗时且成本高(如医学影像标注需专业医生参与)。 - 解决方案
: - 标注一致性与主观性
-
制定详细标注指南(如“遮挡超过70%的目标不标注”)。 -
通过Kappa系数或Fleiss’ Kappa统计标注一致性,淘汰低质量标注员。 -
使用主动学习(Active Learning)优先标注模型不确定的样本,减少主观偏差。 - 挑战
:不同标注员对模糊目标的判断可能存在差异(如“遮挡程度”的阈值)。 - 解决方案
: - 复杂场景的标注难度
-
采用分层标注(先标注大目标,再细化小目标)。 -
使用时间序列信息(如视频帧间插值)辅助标注动态目标。 -
结合多模态数据(如LiDAR点云+图像)提升标注精度。 - 挑战
:小目标、密集目标或动态场景(如人群拥挤)标注易出错。 - 解决方案
:
三、数据标注在机器视觉开发中的价值
- 模型性能的基石
:高质量标注数据可直接提升模型精度(如COCO数据集使目标检测mAP提升20%+)。 - 领域适应的关键
:通过标注特定领域数据(如工业缺陷检测中的划痕、裂纹),使模型适应真实场景。 - 算法创新的驱动力
:标注数据中的长尾分布(如罕见类别)推动少样本学习、零样本学习等算法发展。
四、典型案例
- 自动驾驶
:Waymo开源数据集标注了2000万帧图像中的1200万个3D边界框,支撑其L4级自动驾驶系统。 - 医疗影像
:Kaggle的RSNA肺炎检测竞赛中,标注的胸部X光片数据使模型AUC达到0.98。 - 工业质检
:某电子厂通过标注10万张PCB板图像,训练的缺陷检测模型准确率达99.7%,替代人工目检。
总结
数据标注是机器视觉开发的“数据工程”核心环节,其质量直接影响模型性能。通过标准化流程、高效工具和严格质控,可构建高质量标注数据集,为模型训练提供可靠基础。随着主动学习、弱监督学习等技术的发展,未来标注过程将更智能化,进一步降低人工成本。
开源的交互式视频/图像标注工具
源代码
https://www.gitpp.com/japxin/project0808cvat
专为计算机视觉任务设计,支持目标检测、图像分割、姿态估计等任务
MIT协议,可以自有使用,商业化和二开
本篇文章来源于微信公众号: GitHubFun网站
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END










暂无评论内容