
一站式数据平台开源
源代码
https://www.gitpp.com/opentcs/project0meta-data
提供元数据管理、数据概览报告、数据质量管理,数据分布查询、数据趋势洞察等核心能力。
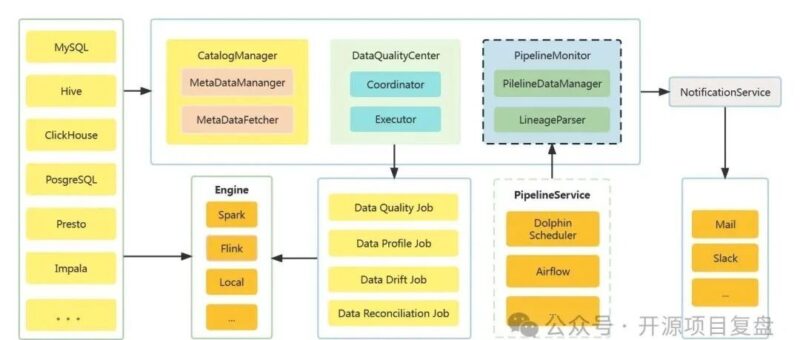
架构设计
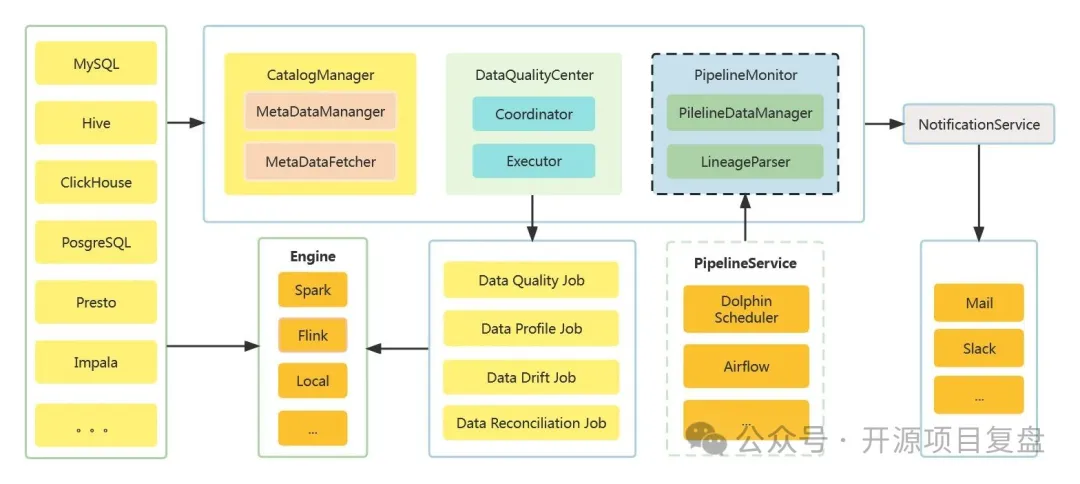
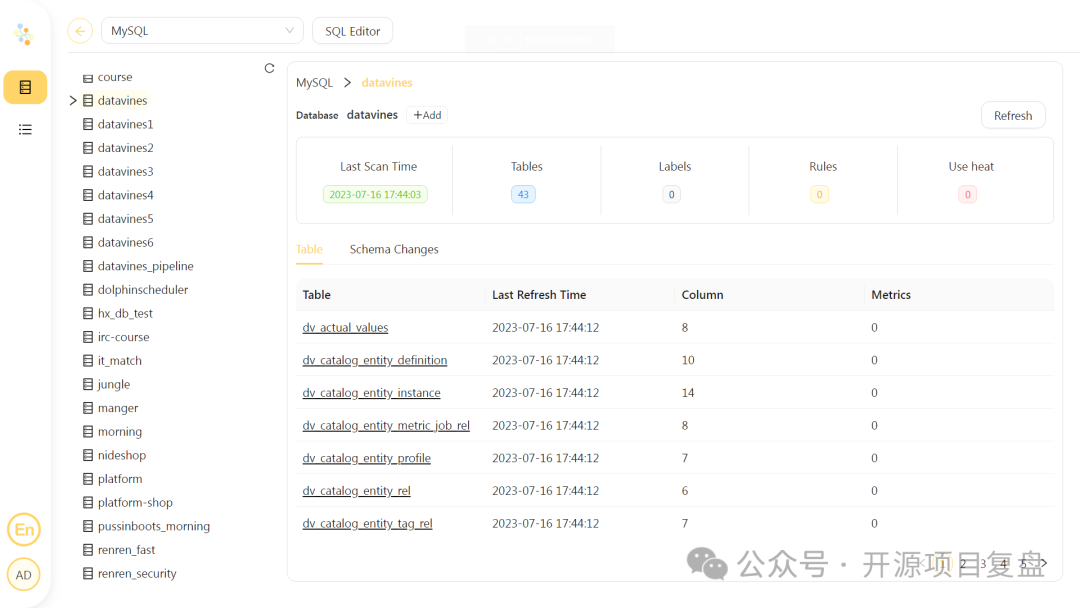
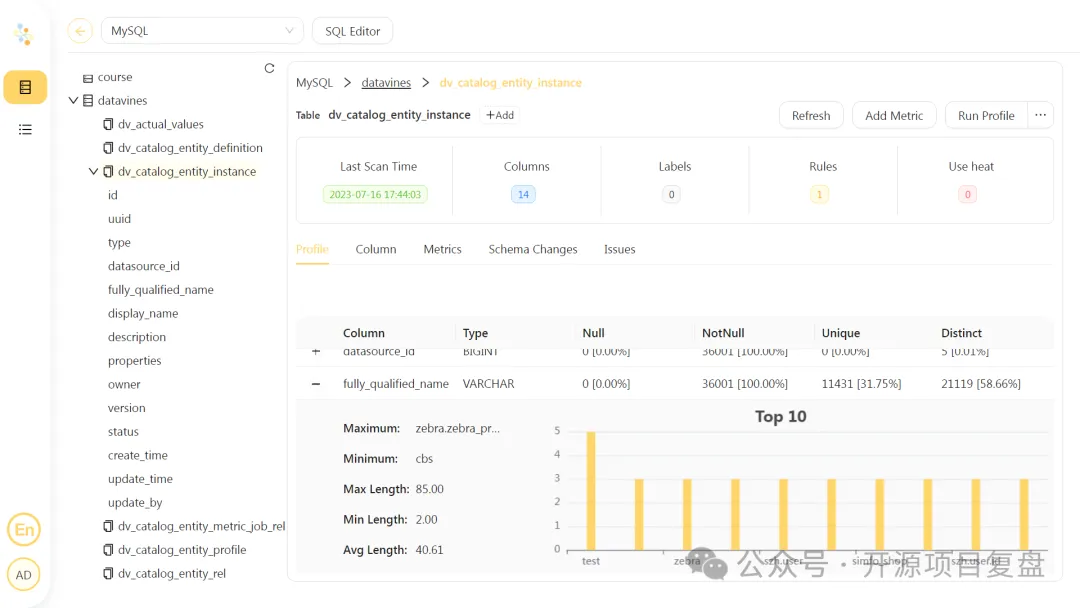
数据目录
-
定时获取数据源元数据,构造数据目录 -
定时监听元数据变更情况 -
支持元数据的标签管理
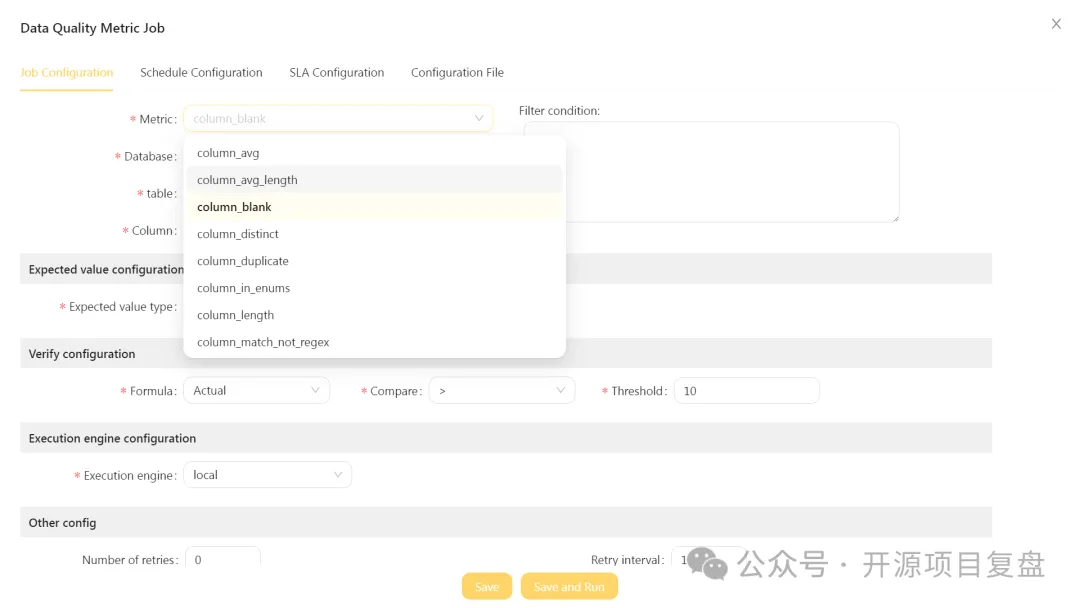
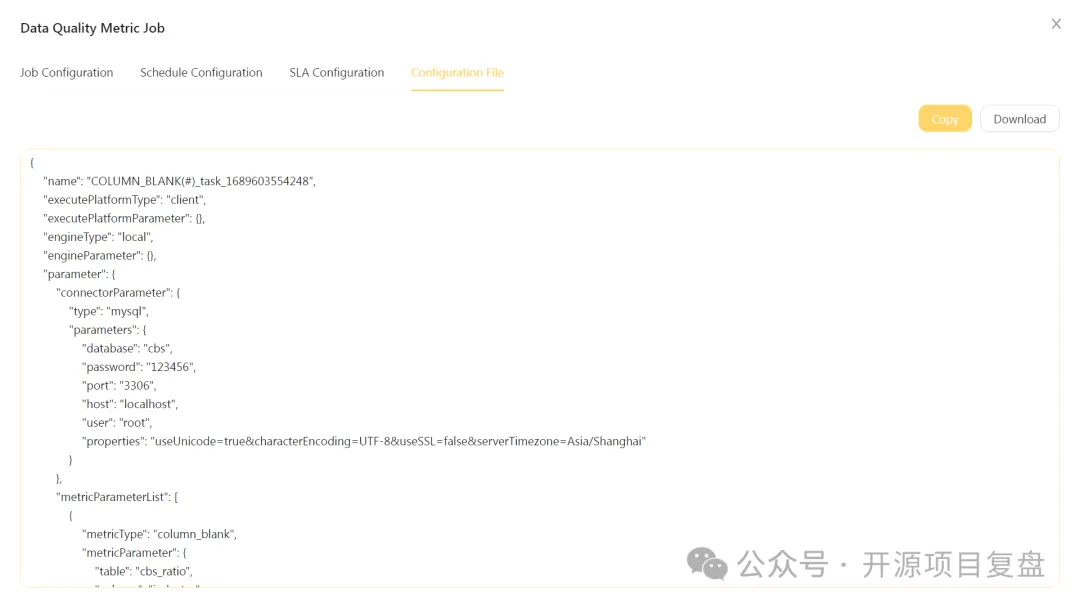
数据质量监控
-
内置 27 个数据质量检查规则,开箱即用 -
支持 4 种数据质量检查规则类型 -
单表单列检查类型 -
单表自定义 SQL检查类型 -
跨表准确性检查类型 -
两表值比对检查类型 -
支持配置定时任务进行定时检查 -
支持配置 SLA用于检查结果告警
数据概览
-
支持定时执行数据探测,输出数据概览报告 -
支持自动识别列的类型自动匹配合适的数据概况指标 -
支持表行数趋势监控 -
支持列的数据分布情况查看
插件化设计
平台以插件化设计为核心,以下模块都支持用户自定义插件进行扩展
- 数据源
:已支持 MySQL、Impala、StarRocks、Doris、Presto、Trino、ClickHouse、PostgreSQL - 检查规则
:内置空值检查、非空检查、枚举检查等27个检查规则 - 作业执行引擎
:已支持 Spark和Local两种执行引擎。Spark引擎目前仅支持Spark2.4版本,Local引擎则是基于JDBC开发的本地执行引擎,无需依赖其他执行引擎。 - 告警通道
:已支持邮件 - 错误数据存储
:已支持 MySQL和 本地文件(仅支持Local执行引擎) - 注册中心
:已支持 MySQL、PostgreSQL和ZooKeeper
多种运行模式
-
提供Web页面配置检查作业、运行作业、查看作业执行日志、查看错误数据和检查结果 -
支持在线生成作业运行脚本,通过 datavines-submit.sh来提交作业,可与调度系统配合使用
容易部署&高可用
-
平台依赖少,容易部署 -
最小仅依赖 MySQL既可启动项目,完成数据质量作业的检查 -
支持水平扩容,自动容错 - 无中心化设计
, Server节点支持水平扩展提高性能 -
作业自动容错,保证作业不丢失和不重复执行
环境依赖
一站式数据平台功能解析与应用场景
一、平台核心功能模块
该开源数据平台以元数据驱动为核心,围绕数据全生命周期管理构建五大核心能力,形成从数据发现到价值挖掘的完整闭环:
- 元数据管理
- 功能
:自动化采集并管理数据库、表、字段等元数据,支持血缘分析、影响分析和数据分类标签。 - 技术实现
:通过解析SQL脚本、日志及API调用,构建数据流向图谱,例如展示订单表如何通过ETL流程关联到物流表。 - 价值
:解决数据孤岛问题,例如在金融风控场景中快速定位客户征信数据来源,避免重复采集。 - 数据概览报告
- 功能
:生成可视化报表展示数据规模、增长趋势及质量评分,支持自定义指标(如空值率、重复率)。 - 场景
:在零售行业,管理者可通过仪表盘实时监控各渠道销售数据质量,及时修正异常值。 - 交互设计
:提供拖拽式报表生成工具,非技术人员10分钟内可完成复杂报表配置。 - 数据质量管理
- 规则引擎
:内置20+预置规则(如主键唯一性、数值范围校验),支持自定义规则扩展。 - 闭环修复
:自动标记问题数据并触发修复流程,例如在医疗数据中纠正患者年龄字段的负值错误。 - 案例
:某银行通过该模块将贷款申请数据错误率从3%降至0.2%,减少人工审核成本。 - 数据分布查询
- 多维分析
:支持按时间、地域、业务线等维度聚合统计,例如分析电商用户行为数据的地域分布。 - 实时检索
:集成Elasticsearch实现毫秒级响应,满足运营人员即时查询需求。 - 技术亮点
:采用列式存储优化查询性能,10亿条数据查询仅需2秒。 - 数据趋势洞察
- 预测模型
:集成Prophet、LSTM等算法,预测销售额、库存等关键指标未来趋势。 - 根因分析
:通过SHAP值解释模型输出,例如识别影响客户流失率的核心因素。 - 应用场景
:在制造业中预测设备故障率,提前30天安排维护计划。
二、技术架构优势
- 插件化设计
-
支持自定义数据源连接器(如MongoDB、Hive),企业可快速接入新型数据库。 -
模块间解耦,例如数据质量规则引擎可独立部署,不影响其他功能运行。 - 云原生支持
-
提供Docker镜像与Kubernetes部署模板,30分钟内可完成集群化部署。 -
动态资源调度,根据查询负载自动扩展计算节点。 - 安全合规
-
集成Apache Ranger实现细粒度权限控制,例如按部门、角色分配数据访问权限。 -
支持数据脱敏,在报表中自动隐藏敏感字段(如身份证号)。
三、典型应用场景
- 制造业数字化转型
-
元数据管理:快速定位设备故障代码定义,减少维修响应时间40%。 -
数据质量:自动校验物料批次号一致性,避免装配错误。 -
趋势洞察:预测产线停机风险,提升整体设备效率(OEE)15%。 - 场景
:某汽车工厂通过平台整合设备传感器数据、生产计划数据及质量检测数据。 - 价值
: - 金融风控升级
-
血缘分析:追踪贷款申请数据流转路径,确保合规性。 -
实时查询:支持风控模型秒级调用客户历史交易数据。 -
趋势预测:识别高风险交易模式,降低坏账率2%。 - 场景
:银行利用平台构建反欺诈数据中台。 - 价值
: - 物流仓储优化
-
数据分布:分析热销商品库存分布,优化货架摆放。 -
质量监控:自动校验订单与物流数据一致性,减少错发率。 -
根因分析:定位拣选效率低下环节,提升出库速度30%。 - 场景
:电商仓库通过平台管理AGV调度数据与库存数据。 - 价值
: - 医疗数据治理
-
元数据分类:按科室、病种标记数据,支持快速检索。 -
数据脱敏:在科研报告中隐藏患者隐私信息。 -
趋势预测:分析疾病发病率季节性变化,提前调配资源。 - 场景
:医院整合电子病历、检验报告及药品库存数据。 - 价值
:
四、开源生态与社区协作
- 低门槛贡献机制
-
提供详细开发文档与API接口,开发者可快速扩展功能(如新增数据源类型)。 -
设立“新手任务”板块,引导初学者参与文档翻译、测试用例编写等轻量级贡献。 - 行业解决方案库
-
社区维护制造业、金融、物流等垂直领域模板,企业可一键导入配置。 -
例如“智能制造数据治理方案”包含预置的元数据模型、质量规则及报表模板。 - 商业化支持路径
-
核心模块采用Apache 2.0开源协议,企业可免费商用。 -
提供企业版订阅服务,包含高级功能(如SaaS化部署、7×24小时支持)及定制开发。
五、未来演进方向
- AI增强分析
-
集成自然语言处理(NLP),支持用户通过语音查询数据(如“显示上月销售额下降原因”)。 -
自动生成数据故事,将复杂分析结果转化为业务建议。 - 多云数据管理
-
支持跨AWS、Azure、阿里云等平台的数据同步与治理,满足全球化企业需求。 -
优化跨云网络传输性能,降低延迟与成本。 - 区块链存证
-
对关键数据操作(如修改、删除)进行区块链存证,确保审计可追溯。 -
应用于金融交易、医疗记录等高合规场景。
结论:该一站式数据平台通过元数据驱动、模块化设计及行业化适配,已成为企业数字化转型的核心基础设施。其价值不仅在于技术开源,更在于通过标准化数据治理流程与智能化分析工具,帮助企业快速释放数据资产价值,驱动业务创新。
一站式数据平台开源
源代码
https://www.gitpp.com/opentcs/project0meta-data
提供元数据管理、数据概览报告、数据质量管理,数据分布查询、数据趋势洞察等核心能力。
本篇文章来源于微信公众号: GitHubFun网站
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END










暂无评论内容