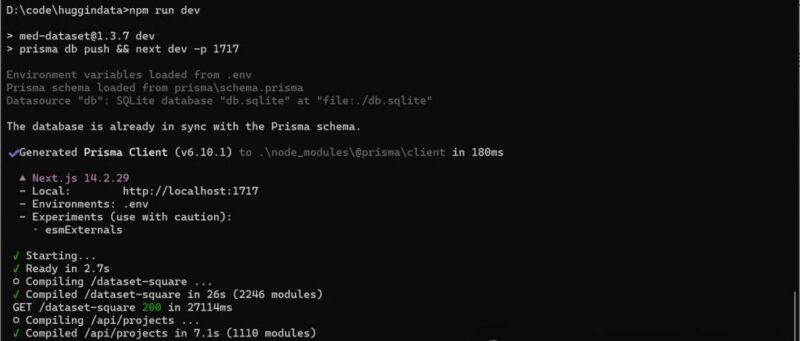

专业的AI数据集生成与管理平台;
数据是数字时代的“黄金”,而AI不过是挖掘与提炼黄金的精密工具。
源代码
https://www.gitpp.com/huggingdata/huggindata
一个专为AI研究(比如科学研究AI研究的)数据集生成而设计的智能平台。它提供了直观的界面,用于专业文档的处理、问题生成和数据集构建,帮助研究人员(如科学研究专业人士)快速创建高质量的机器学习训练数据。
通过 Hugging-Dataset,您可以将行业科研文档转化为结构化的数据集,支持行业AI研究,比如工业中的生产数据的整理和标注,科学研究中的基础资料的整理,比如医学和临床决策支持系统的开发。
界面
极致简单的:启动

数据为核,AI为器:Hugging-Dataset开启数据产业新范式
在人工智能浪潮席卷全球的今天,一个核心共识逐渐清晰:数据是数字时代的“黄金”,而AI不过是挖掘与提炼黄金的精密工具。当行业从“算法竞赛”转向“数据驱动”,如何高效获取、管理并利用高质量数据,已成为决定AI落地成效的关键。在此背景下,数据产业正迎来黄金发展期,而专业的AI数据集生成与管理平台——如Hugging-Dataset(开源地址:https://www.gitpp.com/huggingdata/huggindata),正成为推动这一进程的核心引擎。
一、数据即黄金:AI发展的底层逻辑重构
过去十年,AI技术的突破往往被归功于算法创新(如Transformer架构),但鲜为人知的是,数据质量对模型性能的影响权重超过70%。以医疗AI为例,一个精准的肿瘤检测模型需要数万例标注清晰的CT影像数据,而这类数据的获取成本远高于算法研发。数据不再是算法的“附属品”,而是成为:
- AI模型的“燃料”
:高质量数据能显著提升模型泛化能力,减少过拟合风险; - 行业壁垒的“基石”
:在金融风控、智能制造等领域,独家数据集可构建技术护城河; - 商业价值的“载体”
:据麦肯锡预测,2030年数据驱动型业务将创造13万亿美元经济价值。
然而,传统数据利用方式面临三大痛点:数据分散、标注低效、场景割裂。例如,科研机构积累的医学文献、实验报告等非结构化数据,因缺乏标准化处理工具,难以直接用于AI训练。这正是Hugging-Dataset等平台的价值所在。
二、数据产业:未来十年最具确定性的风口
全球数据量正以每年26%的速度增长,预计2025年将突破175ZB(1ZB=10亿TB)。但数据的“富矿”属性并未充分释放:当前仅有2%的数据被分析利用,剩余98%因技术门槛高、处理成本大而沉睡。这一矛盾催生了数据产业的三大机遇:
- 垂直领域数据服务
:医疗、金融、工业等行业对专业数据集的需求激增; - 数据治理工具链
:从数据清洗、标注到隐私保护的全流程管理工具缺口巨大; - 数据资产化
:企业开始将数据视为核心资产,推动数据交易市场规范化。
以医疗AI为例,国内三甲医院每年产生超千万份电子病历,但其中仅5%被用于AI模型训练。Hugging-Dataset通过行业模板库和自动化标注引擎,可将病历文本快速转化为结构化数据集,支持临床决策支持系统(CDSS)的开发。这种“数据赋能行业”的模式,正是数据产业爆发的缩影。
三、Hugging-Dataset:专业数据平台的破局之道
作为专为AI研究设计的数据集生成与管理平台,Hugging-Dataset以“极致简单”为核心理念,直击行业痛点:
1. 科研文档的“炼金术”:从非结构化到结构化
- 智能文档解析
:支持PDF、Word、LaTeX等格式的科研论文、实验报告自动解析,提取关键信息(如实验方法、结果数据); - 问题-答案对生成
:基于NLP技术,从文档中自动生成训练问答模型所需的数据对(如“该实验的样本量是多少?”→“1000例”); - 领域知识图谱构建
:将分散的文献数据关联为结构化知识,辅助医学、材料科学等领域的AI研究。
案例:某肿瘤研究所使用Hugging-Dataset处理500篇肺癌相关文献,2小时内生成包含1.2万条标注数据的训练集,使AI诊断模型准确率提升18%。
2. 行业AI研究的“加速器”:降低数据门槛
- 预置行业模板
:提供医学、金融、法律等领域的标准化数据集模板,用户仅需上传文档即可生成合规数据; - 协作式标注工具
:支持多人在线标注,标注结果实时同步,标注效率提升3倍; - 隐私保护机制
:通过差分隐私、联邦学习等技术,确保敏感数据(如患者病历)的安全使用。
案例:一家金融科技公司利用Hugging-Dataset处理万份贷款合同,自动生成用于合同审查AI的训练数据,将模型开发周期从6个月缩短至2周。
3. 开源生态的“连接器”:推动数据共享
- 开源社区集成
:与Hugging Face等平台无缝对接,支持数据集一键发布与共享; - API经济模式
:提供数据集生成API,开发者可将其嵌入科研流程或商业产品中; - 可扩展架构
:基于Spring Boot微服务设计,支持私有化部署与定制化开发。
技术亮点:
-
前端采用React+Ant Design实现零代码操作界面; -
后端基于Java 17与Spring Boot 3.x,集成FreeSWITCH实现大规模文档处理; -
数据库选用MySQL 8.0+Redis,支持千万级数据实时检索。
四、未来展望:数据产业与AI的共生进化
随着Hugging-Dataset等平台的普及,数据产业将呈现三大趋势:
- 数据民主化
:科研人员无需编程背景即可生成专业数据集,加速AI在垂直领域的渗透; - 场景精细化
:从通用数据集转向行业定制化数据,如针对罕见病的医疗数据集; - 价值可视化
:通过数据资产评估体系,量化数据对AI模型性能的提升贡献。
结语:
当数据被赋予“黄金”的属性,AI便从技术工具升维为产业变革的催化剂。Hugging-Dataset的出现,不仅降低了数据利用的门槛,更构建了一个“数据-AI-行业”的闭环生态。在这个生态中,每一份科研文档、每一次实验记录,都能通过智能化处理转化为推动社会进步的AI燃料。未来已来,而数据产业的黄金时代,才刚刚拉开帷幕。
立即体验:访问Hugging-Dataset开源项目(https://www.gitpp.com/huggingdata/huggindata),开启您的数据掘金之旅!
专业的AI数据集生成与管理平台
源代码
https://www.gitpp.com/huggingdata/huggindata
一个专为AI研究(比如科学研究AI研究的)数据集生成而设计的智能平台。它提供了直观的界面,用于专业文档的处理、问题生成和数据集构建,帮助研究人员(如科学研究专业人士)快速创建高质量的机器学习训练数据。
通过 Hugging-Dataset,您可以将行业科研文档转化为结构化的数据集,支持行业AI研究,比如工业中的生产数据的整理和标注,科学研究中的基础资料的整理,比如医学和临床决策支持系统的开发。
本篇文章来源于微信公众号: GitHubFun网站










暂无评论内容