

开源大数据平台项目
源代码
https://www.gitpp.com/devvopss/bigdata-platform
主要解决大数据采集、存储、分析与计算问题,主要包括元数据、数据采集、Flink开发,Spark开发,以及资源管理。
Flink和Spark作为核心计算引擎,分别针对流处理与批处理场景提供高性能解决方案,同时与元数据管理、数据采集、资源管理等模块协同,构建完整的实时与离线数据处理能力。
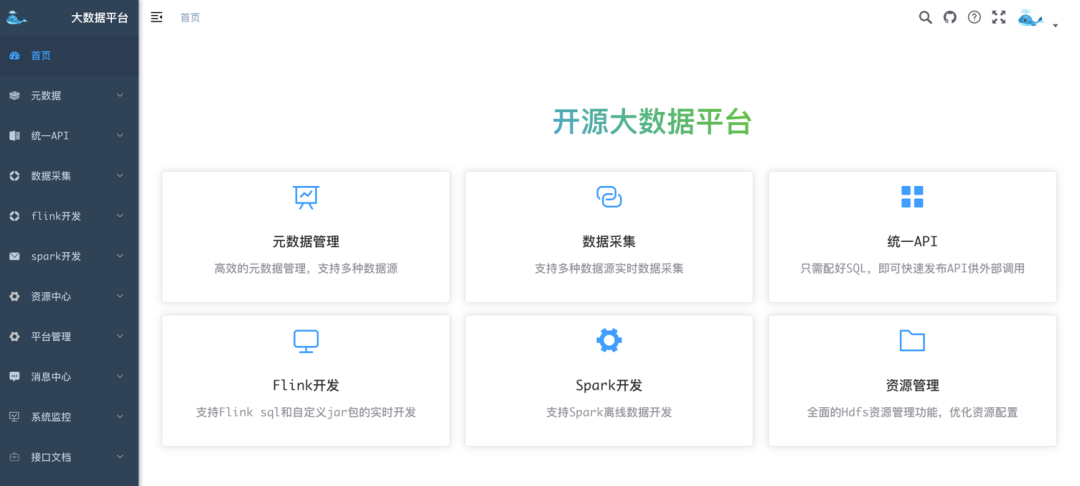
元数据管理、数据采集、统一API、资源管理等
元数据管理


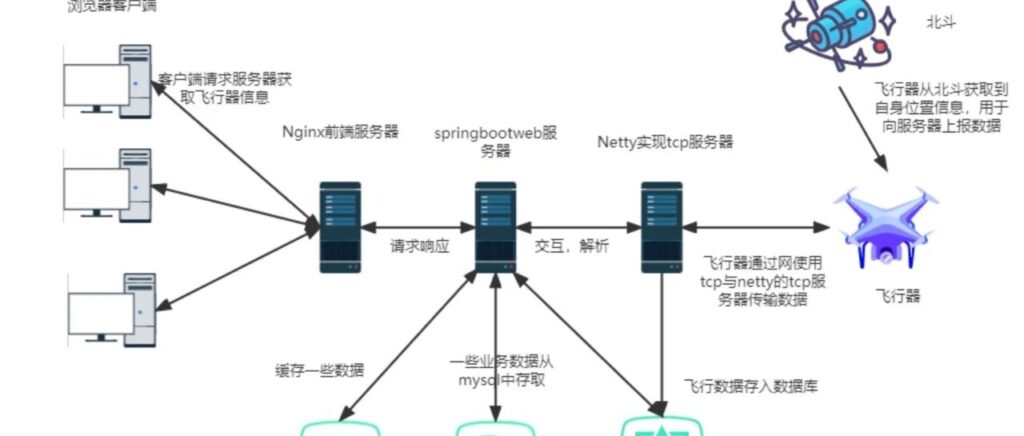
数据采集
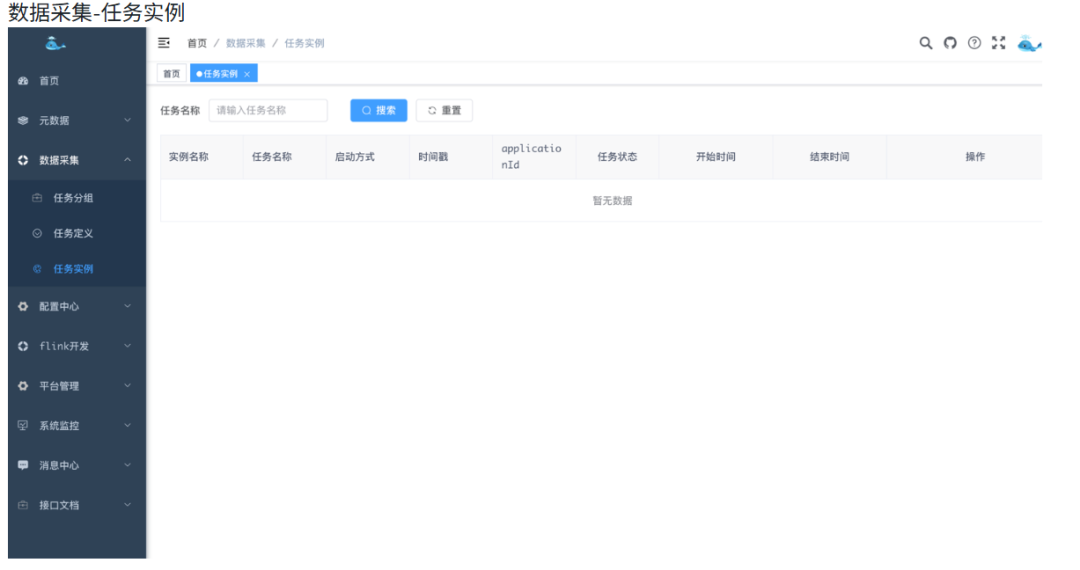
开源大数据平台功能介绍:Flink与Spark的核心作用解析
在开源大数据平台中,Flink和Spark作为核心计算引擎,分别针对流处理与批处理场景提供高性能解决方案,同时与元数据管理、数据采集、资源管理等模块协同,构建完整的实时与离线数据处理能力。
以下是具体功能解析:
一、Flink:实时流处理的核心引擎
- 技术定位
Flink是Apache顶级的开源流批一体化框架,专为低延迟、高吞吐的实时数据处理设计。其核心优势在于: - 统一流批API
:通过 DataStreamAPI同时支持有界(批)和无界(流)数据处理,代码复用率提升50%以上。 - 事件时间与水位线
:精准处理乱序数据,例如在金融交易监控中,即使数据延迟到达,仍能基于事件时间生成准确统计结果。 - 状态管理与容错
:支持分布式状态存储(如RocksDB)和精确一次(Exactly-Once)语义,确保故障恢复后状态一致性。 - 典型应用场景
- 实时数仓
:直接消费Kafka中的用户行为日志,通过Table API/SQL清洗后写入ClickHouse,数据延迟从小时级降至秒级。 - 复杂事件处理(CEP)
:在工业设备监控中,识别“温度异常上升+压力骤降”的故障模式,触发实时告警。 - 实时机器学习
:结合Flink ML库,对用户行为流实时生成特征向量,输入在线模型实现动态推荐。 - 与平台其他模块的协同
- 数据采集
:通过Kafka Connector无缝对接平台采集模块,实时获取物联网传感器数据。 - 资源管理
:支持Kubernetes原生调度,动态扩展TaskManager实例以应对流量峰值。 - 元数据管理
:与平台元数据中心集成,记录Flink作业的输入/输出表结构及血缘关系。
二、Spark:批处理与通用计算的王者
- 技术定位
Spark是基于内存计算的分布式处理框架,以DAG执行引擎和弹性分布式数据集(RDD)为核心,提供: - Spark SQL
:支持结构化数据查询,性能比Hive快3-50倍。 - MLlib
:提供分类、聚类等机器学习算法,如电商用户画像的实时更新。 - GraphX
:处理图结构数据,例如社交网络关系分析。 - 高性能批处理
:内存计算速度比Hadoop MapReduce快10-100倍,适合PB级历史数据回溯分析。 - 丰富的生态组件
: - 典型应用场景
- 离线数据分析
:每日凌晨处理前一日的电商交易数据,生成销售报表并写入关系型数据库。 - 交互式查询
:通过Jupyter Notebook连接Spark集群,支持分析师实时探索TB级用户行为数据。 - 机器学习训练
:利用MLlib的ALS算法,基于历史数据训练商品推荐模型。 - 与平台其他模块的协同
- 数据存储
:直接读取HDFS/HBase中的历史数据,或通过JDBC连接写入MySQL结果表。 - 资源管理
:在YARN集群上提交Spark作业,动态分配Executor资源以优化成本。 - 元数据管理
:通过Hive Metastore集成,自动同步Spark SQL表的元数据信息。
三、Flink与Spark的协同设计
- 场景分工
- Flink
:处理实时性要求高的任务(如实时风控、监控告警),或需要状态管理的场景(如用户会话分析)。 - Spark
:处理大规模离线任务(如历史数据回溯、机器学习训练),或对生态系统依赖强的场景(如与Hive集成)。 - 技术整合方案
- 统一元数据管理
:通过Atlas或DataHub共享Flink和Spark作业的元数据(如数据血缘、字段定义),避免信息孤岛。 - 资源隔离与调度
:利用YARN或Kubernetes为Flink和Spark分配独立资源池,防止流作业因批作业资源抢占导致延迟飙升。 - 数据共享
:通过Alluxio分布式缓存系统共享数据,避免Flink和Spark重复读取存储层数据,提升效率。 - 典型案例
- 实时数仓+离线补充
:Flink实时摄入Kafka数据写入Hudi表;Spark定期对Hudi表进行合并(Compact)和优化,供下游分析使用。 - Lambda架构升级
:用Flink替代传统Lambda架构中的实时层(Storm/Spark Streaming),简化系统复杂度,同时保留Spark批处理层处理历史数据。

开源大数据平台项目
源代码
https://www.gitpp.com/devvopss/bigdata-platform
主要解决大数据采集、存储、分析与计算问题,主要包括元数据、数据采集、Flink开发,Spark开发,以及资源管理。
本篇文章来源于微信公众号: GitHubFun网站
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END










暂无评论内容