
GitHub上爆火的数据工具:面向AI的数据转换工具
源代码
https://www.gitpp.com/nextcloud/project0090-dataindex
专为AI打造的超高性能数据转换框架,核心引擎采用Rust编写。开箱即支持增量处理与数据血缘追踪。提供卓越的开发效率,从第0天起即具备生产就绪能力。

让您轻松实现AI驱动的数据转换,并保持源数据与目标数据的同步。无论是为RAG构建向量索引、创建知识图谱,还是执行任何自定义数据转换——其能力远超SQL范畴。
遵循数据流编程模型理念。每个转换仅基于输入字段生成新字段,没有隐藏状态和值突变。所有转换前后的数据均可观察,并自带数据血缘追踪。
特别之处在于,开发者无需通过创建、更新和删除操作来显式改变数据,只需为源数据集定义转换规则/公式即可。
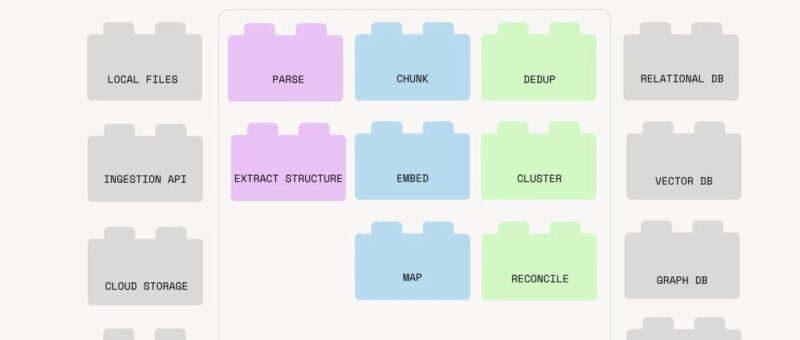
即插即用构建模块
为不同数据源、目标和转换提供原生内置组件。标准化接口,实现不同组件间的一行代码切换——如同搭积木般简单。
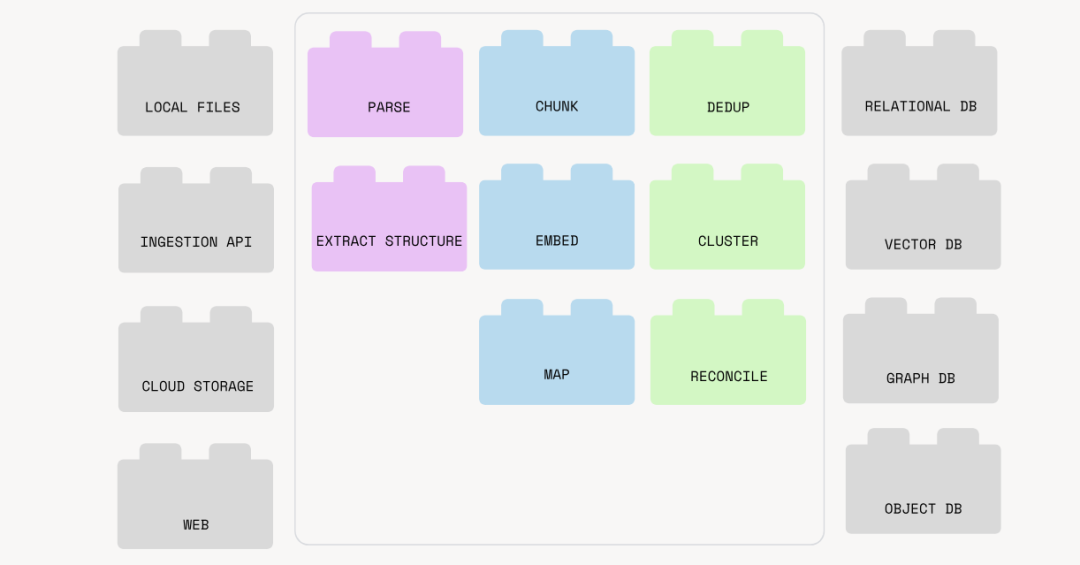
能毫不费力地保持源数据与目标的同步
提供开箱即用的增量索引支持:
-
在源数据或逻辑变更时执行最小化重计算 -
(重新)处理必要部分,尽可能复用缓存
开源平台介绍
一个专为AI场景设计的超高性能数据转换框架,其核心引擎采用 Rust 编写,兼具极致性能与低资源消耗。该框架以 数据流编程模型 为基础,通过声明式转换规则实现数据从源到目标的无缝同步,支持增量处理、数据血缘追踪等企业级功能,且从开发初期即具备生产就绪能力。其核心设计理念是“定义规则而非操作数据”,开发者仅需通过规则/公式描述数据转换逻辑,无需显式编写CRUD代码,即可自动完成复杂的数据管道构建。
核心特性与技术优势
- 超高性能与增量处理
- Rust核心引擎
:利用Rust的零成本抽象和内存安全特性,实现接近原生性能的数据处理,轻松应对海量数据场景。 - 增量索引支持
:当源数据或转换逻辑变更时,自动识别变更部分并执行最小化重计算,通过缓存复用大幅降低计算资源消耗。例如,在RAG向量索引更新中,仅需重新处理新增或修改的文档,而非全量重建索引。 - 数据血缘追踪与可观测性
- 全链路追踪
:记录每个字段的转换路径和依赖关系,支持快速定位数据问题根源。例如,当知识图谱中的实体关系出现异常时,可通过血缘追踪定位到原始数据或转换规则中的错误。 - 无隐藏状态
:所有转换仅基于输入字段生成新字段,避免副作用,确保数据流的可预测性和可调试性。 - 即插即用组件生态
- 标准化接口
:提供原生内置组件,支持多种数据源(如CSV、JSON、SQL数据库、MongoDB)、目标(向量数据库、图数据库、文件系统)及转换操作(NLP清洗、特征提取、聚合计算等)。 - 一行代码切换组件
:例如,将输出从文件系统切换为Neo4j图数据库,仅需修改导出配置中的目标组件类型,无需重构转换逻辑。 - 声明式转换规则
- 规则驱动开发
:开发者通过配置转换规则(如正则表达式、Lambda函数、预置NLP模型)定义数据派生方式,而非编写过程式代码。例如,为文本字段添加“分词”转换规则后,系统会自动生成分词后的新字段。 - 动态规则更新
:支持在运行时动态调整转换规则,无需重启服务即可适应业务变化。
典型应用场景
- RAG(检索增强生成)向量索引构建 优势
-
通过增量处理避免全量索引重建,节省90%以上计算时间。 -
支持自定义文本清洗规则(如去重、纠错、敏感词过滤),确保向量质量。 -
血缘追踪可验证向量与原始文本的对应关系,提升模型可解释性。 - 场景
:从多源数据(PDF、网页、数据库)抽取文本,清洗后生成向量嵌入,并增量更新至向量数据库。 - 动态知识图谱更新 优势
-
增量处理仅更新变更的实体或关系,避免图数据冲突。 -
支持自定义关系抽取规则(如通过正则表达式识别合同中的“甲方-乙方”关系)。 -
血缘追踪可追溯图谱中每个节点的数据来源,满足合规审计需求。 - 场景
:从结构化/非结构化数据中提取实体与关系,构建图数据库(如Neo4j),并实时同步数据变更。 - 实时特征工程与训练集生成 优势
-
流式处理支持低延迟特征计算(如滑动窗口聚合)。 -
支持自定义特征函数(如计算用户最近7天的平均消费金额)。 -
增量处理确保特征与日志数据同步,避免训练集与在线特征不一致。 - 场景
:处理用户行为日志,生成特征并导出为训练集,支持机器学习模型迭代。 - 多源数据同步与ETL 优势
-
即插即用组件支持快速配置数据源与目标连接。 -
声明式规则简化ETL逻辑开发(如字段映射、数据类型转换)。 -
增量处理减少数据同步延迟,支持近实时数据分析。 - 场景
:将分散在多个数据库(MySQL、MongoDB)中的数据同步至数据仓库(Snowflake),并执行清洗、转换操作。
GitHub上爆火的数据工具:面向AI的数据转换工具
源代码
https://www.gitpp.com/nextcloud/project0090-dataindex
专为AI打造的超高性能数据转换框架,核心引擎采用Rust编写。开箱即支持增量处理与数据血缘追踪。提供卓越的开发效率,从第0天起即具备生产就绪能力。
本篇文章来源于微信公众号: GitHubFun网站










暂无评论内容