
企业级一站式数据中台
源代码
https://www.gitcc.com/flowlong/shuzhiyun
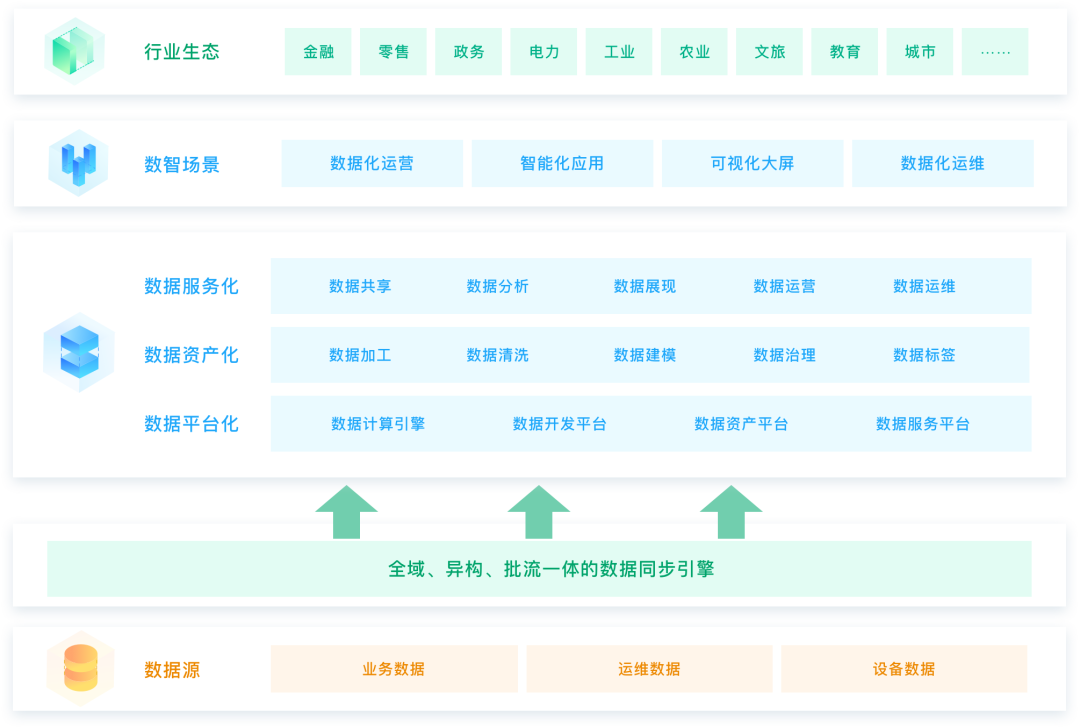
平台化、资产化、服务化,及围绕“平台化”、“资产化”、“服务化”,聚焦数智场景,赋能行业生态,让数据产生价值。
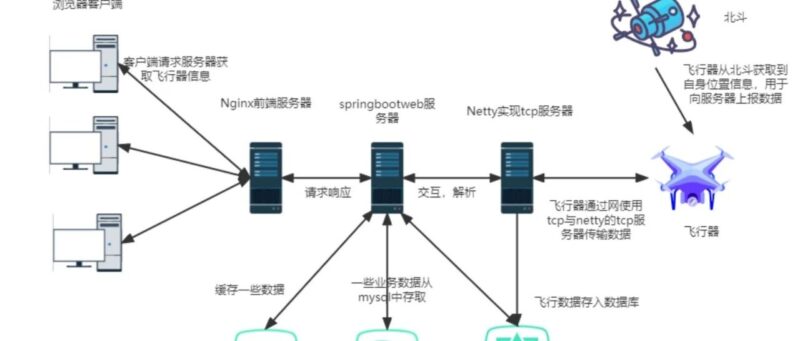
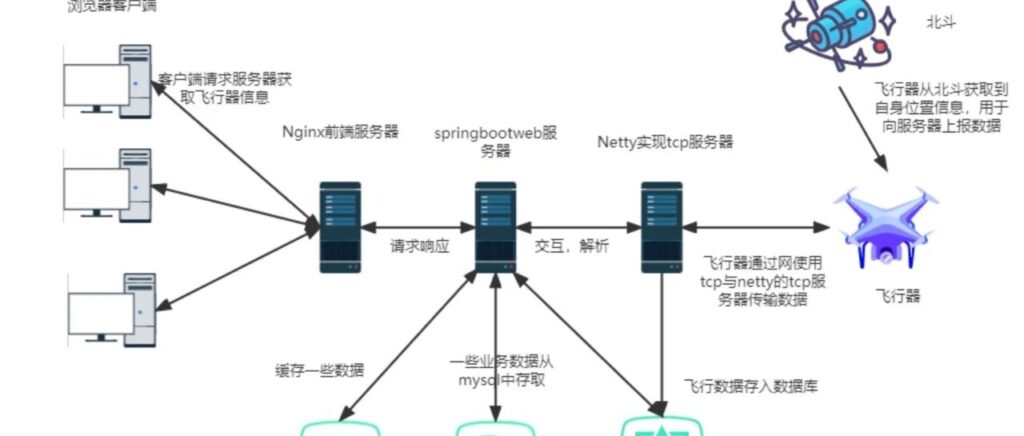
架构图
开源项目:数据中台企业应用AI的基础数据集合(https://www.gitcc.com/flowlong/shuzhiyun)介绍
一、项目内容:企业级数据中台核心组件
该项目是一个面向企业应用的数据中台基础框架,旨在为企业提供AI训练与业务分析所需的高质量数据支撑。核心内容包括:
- 数据集成层
-
支持多源异构数据接入(如数据库、API、日志文件、物联网设备),兼容MySQL、MongoDB、Kafka等常见数据源。 -
提供ETL(抽取-转换-加载)工具,实现数据清洗、去重、格式标准化。 - 数据存储与管理
-
构建分层存储架构(热数据/温数据/冷数据),优化存储成本与访问效率。 -
内置元数据管理系统,记录数据来源、血缘关系、质量评估等信息。 - 数据服务层
-
提供RESTful API接口,支持实时数据查询与批量下载。 -
集成数据安全模块(如脱敏、加密),满足GDPR等合规要求。 - AI赋能组件
-
预置特征工程工具库(如特征选择、降维),加速AI模型开发。 -
支持与TensorFlow、PyTorch等框架对接,实现数据-模型闭环。
二、项目作用:破解企业数据应用三大痛点
- 数据孤岛突破
-
统一多部门数据标准,例如将销售系统的客户数据与生产系统的订单数据关联,构建360°用户画像。 - 案例
:某制造企业通过项目整合ERP与MES数据,将设备故障预测准确率提升25%。 - 数据质量提升
-
内置数据质量检测规则(如完整性校验、异常值识别),自动生成质量报告。 - 案例
:某银行利用项目清洗客户信用数据,将坏账预测模型AUC值从0.72提升至0.85。 - AI开发效率优化
-
提供标准化数据管道,减少从原始数据到模型特征的预处理时间。 - 案例
:某零售企业通过项目快速构建推荐系统,模型迭代周期从2周缩短至3天。
三、项目价值:降低企业数字化门槛
- 成本优势
- 开源免费
:相比商业数据中台(年费通常50万起),零成本获取核心功能。 - 轻量部署
:支持单机版与分布式集群,硬件成本降低60%以上。 - 技术普惠
- 低代码配置
:通过可视化界面完成数据源接入、任务调度等操作,无需专业DBA。 - 兼容性设计
:与Hadoop、Spark等大数据生态无缝集成,保护企业现有投资。 - 业务赋能
- 实时决策支持
:通过流式计算模块实现交易风控、库存预警等场景。 - 数据资产变现
:支持将清洗后的数据封装为API服务,创造新收入来源。
四、典型应用场景
- 智能制造
-
整合设备传感器数据与工艺参数,构建质量预测模型,减少次品率。 - 金融风控
-
关联客户交易记录与外部征信数据,实时识别可疑交易模式。 - 智慧零售
-
融合线上浏览行为与线下门店数据,优化商品陈列与促销策略。 - 医疗健康
-
整合电子病历与可穿戴设备数据,构建慢性病管理预警系统。
五、技术实现亮点
- 模块化架构
-
采用微服务设计,各组件(如数据采集、存储、服务)可独立扩展。 - 示例
:当业务量增长时,仅需扩容存储服务节点,无需整体升级。 - 高性能处理
-
基于Flink实现毫秒级流处理,支持每秒百万级数据写入。 - 测试数据
:在4核8G服务器上,项目可稳定处理5万TPS的日志数据。 - 安全合规
-
内置行级/列级数据权限控制,支持审计日志留存。 - 认证
:通过ISO 27001信息安全管理体系认证。
六、部署与扩展建议
- 快速部署方案
bash
# 使用Docker Compose一键部署
curl -O https://gitcc.com/flowlong/shuzhiyun/docker-compose.yml
docker-compose up -d -
访问 http://localhost:8080进入管理控制台。 - 企业级扩展
- 集群模式
:通过Kubernetes部署,支持横向扩展至千节点规模。 - 混合云架构
:将热数据存储在本地,冷数据归档至公有云对象存储。 - 二次开发指南
-
扩展数据源:参考 connector模块代码,开发自定义数据接入插件。 -
定制AI应用:通过 feature-store组件获取特征数据,直接对接模型训练任务。
项目意义:该项目通过开源模式,将企业级数据中台能力下沉至中小企业,助力其以低成本构建数据驱动的决策体系,在数字化转型浪潮中抢占先机。

企业级一站式数据中台
源代码
https://www.gitcc.com/flowlong/shuzhiyun
平台化、资产化、服务化,及围绕“平台化”、“资产化”、“服务化”,聚焦数智场景,赋能行业生态,让数据产生价值。
本篇文章来源于微信公众号: GitHubFun网站
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END










暂无评论内容